
ก่อนจะทำอาหารต้องสรรหาวัตถุดิบฉันใด ก่อนจะทำ Data ก็ต้องหาข้อมูลฉันนั้น หากไม่มีวัตถุดิบซึ่งเป็น Data ต่าง ๆ ก็คงจะเริ่มได้ไม่ดีนัก เรื่องการ Getting Data หรือการได้มาซึ่งข้อมูล จึงเป็นส่วนสำคัญใน Data Science
และวิธีการหนึ่งในการ รับข้อมูล มานั้นคือการ Scrape จากเว็บ ในวัยเรียนหลาย ๆ คน คงเคยทำรายงานส่งโดยการค้นหาจากใน Google และกด Copy Paste มาแปะบนรายงานต่าง ๆ ไม่มากก็น้อย หรือทั้งรายงานมาจากเว็บเลยก็มี จนบางทีโดนอาจารย์ให้ไปทำใหม่ การ Scrape ก็เป็นวิธีหนึ่งที่คล้าย ๆ กัน แต่เข้าไปเอาข้อมูลมาโดยโปรแกรม
Scrape = ขูด, ไถ
ถ้าให้พูดการ Web Scrape มันก็เหมือนการไล่ขูดไปบนหน้าเว็บไซต์ต่าง ๆ และดึงข้อมูลมาเก็บไว้ มาเป็น Data
คำเตือน : Web Scrape เป็นการกระทำที่สีเทา ๆ อาจจะผิดกฎหมายได้ เพราะเหมือนเราไปดูดข้อมูลชาวบ้านเค้ามาใช้ บางทีก็อาจจะต้องอ่านกฏต่าง ๆ ของเว็บที่เราจะไปโหลดไว้ด้วยครับ (แน่นอนว่าเราไม่สามารถ Scrape บนหน้า Search ของ Google ได้ )
วันนี้ผมมาจะมาแนะนำการใช้งาน rvest Library ของ R ที่จะช่วยให้เราดูดข้อมูล Scrape จากหน้าเว็บได้ง่ายขึ้น
ความรู้เบื้องต้นที่ควรมี
- ภาษา R
- โครงสร้าง HTML คร่าว ๆ
การ Scrape ของ rvest ถ้าอธิบายง่าย ๆ คือ 3 ขั้น คือ
เข้า เลือก ดูด
เข้า คือเข้าไปยังหน้าเว็บที่ต้องการ
เลือก คือการเลือก Element ในส่วนที่ต้องการจะดึงข้อมูล
ดูด คือการดึงข้อมูลใน Element นั้น ๆ ที่เลือกมาเก็บไว้
(Element คือ ส่วนประกอบของหน้าเว็บ ที่เขียนขึ้นโดย HTML มีลักษณะเป็น Tag <tagname></tagname>)
โดยเราสามารถดูได้ง่าย ๆ ด้วยการ Inspect Element จาก Web Browser
อาจจะยังไม่เห็นภาพ งั้นมาลองยกตัวอย่างการดูดข้อมูลรางวัลที่ 1 และเลขท้ายสองตัว จากเว็บนี้เอง datasciya.com กันครับ
ขั้นแรกสู่สายดูด
เริ่มแรก ให้เราจำลองว่าตัวเองเป็นโปรแกรม เพื่อหาขั้นตอนการทำงาน โดยการลองเข้าไปดูในเว็บว่า เราจะเข้าไปหาสิ่งที่เราต้องการ (รางวัลที่ 1 และ เลขท้าย 2 ตัว) โดยใช้ข้อมูลจากเว็บนี้เอง โดยเข้าไปที่หน้าของ ผลสลากกินแบ่งรัฐบาล ซึ่งเป็นหน้าเว็บที่เป็นส่วน Category ของผลลอตเตอรี่บนเว็บนี้
https://www.datasciya.com/category/ผลสลากกินแบ่งรัฐบาล/
หมายเหตุ : ในส่วนนี้จะพูดถึงเรื่องการเลือก Elements ใน HTML หากคนที่ไม่คุ้นให้ลองทำตามไปก่อนครับ ไม่ยากครับ
ผมจะยกตัวอย่างโดยใช้ Chrome นะครับ เมื่อเข้าไปในหน้าเว็บ ผลสลากกินแบ่งรัฐบาล
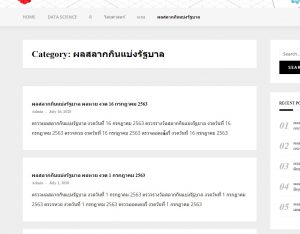
จะเห็นในหน้านี้มีลิสต์ผลสลากกินแบ่งรัฐบาลทั้งหมด โดยเราจะเลือก “เข้า” ไปดูทุกหน้าเพื่อเก็บข้อมูล
ทีนี้ลองคลิกขวาที่บริเวณลิงก์ที่เราจะเข้าไปยกตัวอย่างของงวดล่าสุดคือแล้วเลือก Inspect Browser อื่น ๆ จะชื่อประมาณ Inspect Element
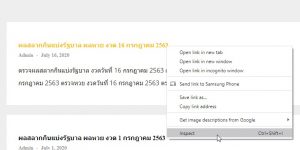
Browser จะแสดงหน้าต่าง DevTools ที่แสดง HTML ของหน้าเว็บขึ้นมา โดยจะระบุไปที่ Element ที่เราได้คลิกขวาเลือกไป
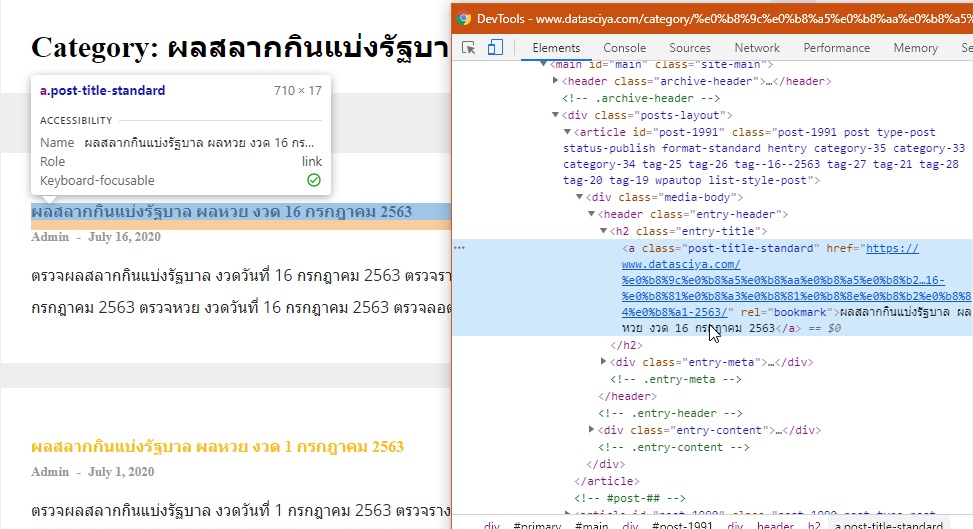
จะเห็นว่าเรา Element ที่ต้องการเพื่อให้หา Url Link ของแต่ละงวดคือ
<class="post-title-standard" href="https://www.datasciya.com/%e0%b8%9c%e0%b8%a5%e0%b8%aa%e0%b8%a5%e0%b8%b2%e0%b8%81%e0%b8%81%e0%b8%b4%e0%b8%99%e0%b9%81%e0%b8%9a%e0%b9%88%e0%b8%87%e0%b8%a3%e0%b8%b1%e0%b8%90%e0%b8%9a%e0%b8%b2%e0%b8%a5/16-%e0%b8%81%e0%b8%a3%e0%b8%81%e0%b8%8e%e0%b8%b2%e0%b8%84%e0%b8%a1-2563/" rel="bookmark">ผลสลากกินแบ่งรัฐบาล ผลหวย งวด 16 กรกฎาคม 2563</a>
จะพบว่าตัวอย่าง Element นี้คือ <a></a> ซึ่ง tag ตัวนี้จะเป็นตัวทำให้เกิด Link บนหน้าเว็บ โดยภายใน Tag จะมี attributes หรือค่าต่าง ๆ เพื่อใช้ระบุว่าเราจะเลือก tag a ตัวไหน โดยในที่นี้เราต้องการ link URL ที่อยู่ใน attribute href ดังนั้นจะได้ดังนี้
เก็บ URL ใน href จาก tag <a> ที่มี class = “post-title-standard”
เมื่อลองคลิกเข้าไปตามลิงก์แต่ละงวด เราก็จะใช้วิธีเดียวกันในการเก็บค่า “รางวัลที่ 1” และ “เลขท้าย 2 ตัว” มาโดยการ คลิกขวา Inspect ที่เลขรางวัลที่ 1 และ เลขท้าย 2 ตัว เหมือน
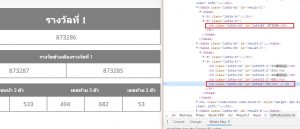
<!-- Element รางวัลที่ 1 -->; <td class="lotto-td" id="lottoB1">873286</td> <!-- Element เลขท้าย 2 ตัว -->; <td class="lotto-td" id="lotto2">53</td>
จะเห็นว่าเราต้องการเลขที่ถูกรางวัล คือ 873286 และ 53 ซึ่งอยู่ใน tag <td>…</td> ขอเรียกข้อมูลข้างใน tag ว่า innerHTML (ใน javascript จะใช้ชื่อนี้)
ดังนั้นเราจะได้ขั้นตอนคือ
รางวัลที่ 1 : เก็บข้อมูล innerHTML จาก tag <td> ที่มี id = “lottoB1”
เลขท้าย 2 ตัว : เก็บข้อมูล innerHTML จาก tag <td> ที่มี id = “lotto2”
แล้วขั้นตอนเราก็จะวนไปเข้าหน้า URL ของงวดถัดไปเรื่อย ๆ
ทีนี้เราจะได้ขั้นตอนที่เราจะเขียนโปรแกรมได้ประมาณนี้
- เก็บ URL ใน href จาก tag <a> ที่มี class = “post-title-standard” จากหน้า https://www.datasciya.com/category/ผลสลากกินแบ่งรัฐบาล/
- วน Loop เข้าทุก URL ที่เราเก็บได้
- เก็บข้อมูล
รางวัลที่ 1 : เก็บข้อมูล innerHTML จาก tag <td> ที่มี id = “lottoB1”
เลขท้าย 2 ตัว : เก็บข้อมูล innerHTML จาก tag <td> ที่มี id = “lotto2”- วนจนครบตามที่ต้องการก็เป็นอันเสร็จพิธี
พอเราได้ขั้นตอนดังกล่าว เดี๋ยวเราจะนำไปเขียนเป็นคำสั่งใน R ด้วย library rvest ในตอนหน้าครับ
ยังไงก็อย่าลืมติดตามกันนะครับ
ป.โท วิศวกรรมศาสตร์ คอมพิวเตอร์
ที่สนใจเรื่อง Data Science และ ไสยศาสตร์
เผื่อซักวันจะถูกหวย รวยเข้าซักวัน